Python知识点大全

Python知识点大全
Andy YinPython基础
变量的命名和使用
变量名只能包含字母、数字和下划线。变量名可以字母或下划线打头,但不能以数字打头,例如,可将变量命名为
message_1,但不能将其命名为1_message。变量名不能包含空格,但可使用下划线来分隔其中的单词。例如,变量名
greeting_message可行,但变量名greeting message会引发错误。不要将Python关键字和函数名用作变量名,即不要使用Python保留用于特殊用途的单词,如
print。变量名应既简短又具有描述性。例如,
name比n好,student_name比s_n好,name_length比length_of_persons_name好。慎用小写字母l和大写字母O,因为它们可能被人错看成数字1和0。
注释
单行注释
Python 中单行注释以 # 开头
例如:
1 | # 这是一个注释 |
多行注释
多行注释用三个单引号 ‘’’ 或者三个双引号 “”” 将注释括起来
例如:
单引号(’’’)
1 | ''' |
双引号(”””)
1 | """ |
进制转换
十进制转N进制
1 | # 获取用户输入十进制数 |
二进制转N进制
1 | binary_number = '101010' |
八进制转N进制
1 | octal_number = '52' |
十六进制转N进制
1 | hexadecimal_number = '2a' |
字符串(String)
访问字符串的值
Python 访问子字符串,可以使用方括号来截取字符串,如下实例:
1 | var1 = 'Hello World!' |
转义字符
在需要在字符中使用特殊字符时,python 用反斜杠\转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \‘ | 单引号 |
| \“ | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 |
| \xyy | 十六进制数,以 \x 开头,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
如果不希望前置 \ 的字符转义成特殊字符,可以使用 原始字符串,在引号前添加 r 即可:
1 | print('C:\some\name') |
字符串运算符
下表实例变量 a 值为字符串 “Hello”,b 变量值为 “Python”:
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | >>>a + b ‘HelloPython’ |
| * | 重复输出字符串 | >>>a * 2 ‘HelloHello’ |
| [] | 通过索引获取字符串中字符 | >>>a[1] ‘e’ |
| [ : ] | 截取字符串中的一部分 | >>>a[1:4] ‘ell’ |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | >>>”H” in a True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | >>>”M” not in a True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母”r”(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r’\n’ \n >>> print R’\n’ \n |
字符串格式化
基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
实例:
1 | print("My name is %s and weight is %d kg!" % ('Zara', 21)) |
多行字符串
三引号
Python 中三引号可以将复杂的字符串进行赋值。
Python 三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
三引号的语法是一对连续的单引号或者双引号(通常都是成对的用)。
1 | s = """My Name is Pankaj. |
续航符
1 | sql = "select * " \ |
括号
1 | sql = ("select *" |
内建函数
upper()、lower()、title()
将字符串进行大小写或标题化。
string.upper()
- 转换 string 中的小写字母为大写
string.lower()
- 转换 string 中所有大写字符为小写
string.title()
- 返回”标题化”的 string,就是说所有单词都是以大写开始,其余字母均为小写
1 | name = "Ada Lovelace" |
strip()
删除字符串的空格。
string.strip()
- 在 string 上执行 lstrip()和 rstrip(),删除string首尾的空格
string.lstrip()
- 截掉 string 开头的空格
string.rstrip()
- 删除 string 末尾的空格
1 | favorite_language = ' python ' |
count()
返回 sub 在 string 里面出现的次数。
string.count(sub, start= 0, end=len(string))
- sub – 搜索的子字符串
- start – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
- end – 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
1 | str="1011011" |
split()
以 str 为分隔符截取字符串。
string.split(str="", num=string.count(str))
str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num – 分割次数。默认为 -1, 即分隔所有。
返回值返回分割后的字符串列表。
1 | str = "this is string example....wow!!!" |
1 | url = "http://www.baidu.com/python/image/123456.jpg" |
replace()
string.replace(old, new[, max])
- old – 将被替换的子字符串。
- new – 新字符串,用于替换old子字符串。
- max – 可选, 替换不超过 max 次
1 | str = "www.w3cschool.cc" |
find()
检测 str 是否包含在字符串string中。
string.find(str, beg=0, end=len(string))
- str – 指定检索的字符串
- beg – 开始索引,默认为0。
- end – 结束索引,默认为字符串的长度。
1 | str1 = "Runoob example....wow!!!" |
join()
join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
string.join(sequence)
- sequence – 要连接的元素序列。
1 | s1 = "-" |
isxxx()
判断字符串是否是字母或数字或空白
string.isalnum()
判断字符串是否是字母或数字
string.isalpha()
判断字符串是否是字母或中文字
string.isdigit()
判断字符串是否是数字
string.isnumeric()
判断字符串是否是数字字符
string.isspace()
判断字符串是否只包含空白
1 | str1 = "runoob2016" |
format()
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
1 | "{} {}".format("hello", "world") |
1 | print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com")) |
数字格式化
下表展示了 str.format() 格式化数字的多种方法:
1 | print("{:.2f}".format(3.1415926)) |
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:-.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:>10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 | '{:b}'.format(11) '{:d}'.format(11) '{:o}'.format(11) '{:x}'.format(11) '{:#x}'.format(11) '{:#X}'.format(11) |
1011 11 13 b 0xb 0XB |
进制 |
^, <, > 分别是居中、左对齐、右对齐,后面带宽度
:号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
+ 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
此外我们可以使用大括号{}来转义大括号,如下实例:
1 | print ("{} 对应的位置是 {{0}}".format("runoob")) |
f-string
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去,实例如下:
1 | name = 'Runoob' |
列表(List)
列表由一系列按特定顺序排列的元素组成。你可以创建包含字母表中所有字母、数字0~9或所有家庭成员姓名的列表;也可以将任何东西加入列表中,其中的元素之间可以没有任何关系。
与元组对比,列表的长度可变、内容可以被修改。你可以用方括号定义,或用list函数:
1 | list1 = ['physics', 'chemistry', 1997, 2000] |
list函数常用来在数据处理中实体化迭代器或生成器:
1 | gen = range(10) |
访问列表值
在Python中,第一个列表元素的索引为0,而不是1。
Python为访问最后一个列表元素提供了一种特殊语法。通过将索引指定为-1,可让Python返回最后一个列表元素:
1 | list1 = ['physics', 'chemistry', 1997, 2000] |
切片
用切边可以选取大多数序列类型的一部分,切片的基本形式是在方括号中使用start:stop:
切片的起始元素是包括的,不包含结束元素。因此,结果中包含的元素个数是stop - start。
start或stop都可以被省略,省略之后,分别默认序列的开头和结尾:
1 | seq = [7, 2, 3, 6, 3, 5, 6, 0, 1] |
下图展示了正整数和负整数的切片。在图中,指数标示在边缘以表明切片是在哪里开始哪里结束的。

在第二个冒号后面使用step,可以隔一个取一个元素:
1 | seq[::2] |
一个聪明的方法是使用-1,它可以将列表或元组颠倒过来:
1 | seq[::-1] |
添加元素
list.append(obj)
- 用于在列表末尾添加新元素。
1 | motorcycles = ['honda', 'yamaha', 'suzuki'] |
插入元素
list.insert(index, obj)
- 用于将指定对象插入列表的指定位置。为此,你需要指定新元素的索引和值。
1 | motorcycles = ['honda', 'yamaha', 'suzuki'] |
1 | aList = [123, 'xyz', 'zara', 'abc'] |
警告:与
append相比,insert耗费的计算量大,因为对后续元素的引用必须在内部迁移,以便为新元素提供空间。如果要在序列的头部和尾部插入元素,你可能需要使用collections.deque,一个双尾部队列。
删除元素
del 语句
使用 del 语句可以从一个列表中根据索引来删除一个元素,而不是值来删除元素。这与使用pop() 返回删除的元素值不同。
1 | motorcycles = ['honda', 'yamaha', 'suzuki'] |
list.remove(obj)
用于移除列表中某个值的第一个匹配项。
remove()只删除第一个指定的值。如果要删除的值可能在列表中出现多次,就需要使用循环来判断是否删除了所有这样的值。
1 | aList = [123, 'xyz', 'zara', 'abc', 'xyz'] |
1 | aList = [123, 'xyz', 'zara', 'abc','xyz','xyz','xyz'] |
list.pop([index=-1])
- 用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
1 | motorcycles = ['honda', 'yamaha', 'suzuki'] |
1 | list1 = ['Google', 'Runoob', 'Taobao'] |
list.clear()
- 用于清空列表,类似于 **del a[:]**。
1 | list1 = ['Google', 'Runoob', 'Taobao', 'Baidu'] |
扩展列表
list.extend(seq)
- 用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)。
- seq – 元素列表,可以是列表、元组、集合、字典,若为字典,则仅会将键(key)作为元素依次添加至原列表的末尾。
1 | list1 = ['Google', 'Runoob', 'Taobao'] |
1 | # 语言列表 |
组织排序
list.sort(cmp=None, key=None, reverse=False)
- sort()函数用于对原列表进行原地排序(不创建新的对象),如果指定参数,则使用比较函数指定的比较函数。
1 | cars = ['bmw', 'audi', 'toyota', 'subaru'] |
1 | vowels = ['e', 'a', 'u', 'o', 'i'] |
1 | b = ['saw', 'small', 'He', 'foxes', 'six'] |
反转顺序
list.reverse()
- reverse() 函数用于反向列表中元素。方法reverse()永久性地修改列表元素的排列顺序。
1 | aList = [123, 'xyz', 'zara', 'abc', 'xyz'] |
获取列表长度
len(list)
- 使用函数len()可快速获悉列表的长度。
1 | cars = ['bmw', 'audi', 'toyota', 'subaru'] |
匹配位置
list.index(x[, start[, end]])
- x– 查找的对象。
- start– 可选,查找的起始位置。
- end– 可选,查找的结束位置。
1 | list1 = ['Google', 'Runoob', 'Taobao'] |
脚本操作符
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代 |
列表推导式
列表推导式格式为:
[表达式 for 变量 in 列表][out_exp_res for out_exp in input_list]
或者
[表达式 for 变量 in 列表 if 条件][out_exp_res for out_exp in input_list if condition]
- out_exp_res:列表生成元素表达式,可以是有返回值的函数。
- for out_exp in input_list:迭代 input_list 将 out_exp 传入到 out_exp_res 表达式中。
- if condition:条件语句,可以过滤列表中不符合条件的值。
实例
1 | names = ['Bob','Tom','alice','Jerry','Wendy','Smith'] |
1 | multiples = [i for i in range(30) if i % 3 == 0] |
元组(Tuple)
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
创建元组
元组是一个固定长度,不可改变的Python序列对象。创建元组的最简单方式,是用逗号分隔一列值:
1 | # 小括号 |
创建空元组
1 | tup1 = () |
元组中只包含一个元素时,需要在元素后面添加逗号
1 | tup1 = (1,) |
用tuple可以将任意序列或迭代器转换成元组:
1 | print(tuple([4, 0, 2])) |
修改元组
元组中存储的对象可能是可变对象。一旦创建了元组,元组中的对象就不能修改了:
1 | tup = tuple(['foo', [1, 2], True]) |
元组中的元素值是不允许修改的,但我们可以对元组用加法运算符进行连接组合
1 | tup1 = (12, 34.56) |
如果元组中的某个对象是可变的,比如列表,可以在原位进行修改:
1 | tup = tuple(['foo', [1, 2], True]) |
删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
1 | tup = ('physics', 'chemistry', 1997, 2000) |
访问元组
| Python 表达式 |描述 |
| :———— | :—————- | :————————— |
| L[2] | 读取第三个元素 |
| L[-2] | 反向读取,读取倒数第二个元素 |
| L[1:] | 截取元素 |
迭代元组
元组是可迭代对象,可以使用for…in进行遍历
1 | t = tuple(('Python', 'Java', 'C#')) |
拆分元祖
如果你想将元组赋值给类似元组的变量,Python会试图拆分等号右边的值:
1 | tup = (4, 5, 6) |
即使含有元组的元组也会被拆分:
1 | tup = 4, 5, (6, 7) |
变量拆分常用来迭代元组或列表序列:
1 | seq = [(1, 2, 3), (4, 5, 6), (7, 8, 9)] |
Python允许从元组的开头“摘取”几个元素。它使用了特殊的语法*rest,这也用在函数签名中以抓取任意长度列表的位置参数:
1 | values = 1, 2, 3, 4, 5 |
rest的部分是想要舍弃的部分,rest的名字不重要。作为惯用写法,许多Python程序员会将不需要的变量使用下划线:
1 | a, b, *_ = values |
因为元组的大小和内容不能修改,它的实例方法都很轻量。其中一个很有用的就是count(也适用于列表),它可以统计某个值得出现频率:
1 | a = (1, 2, 2, 2, 3, 4, 2) |
运算符
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| (‘Hi!’,) * 4 | (‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’) | 复制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print x, | 1 2 3 | 迭代 |
元组推导式
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
元组推导式基本格式:
(expression for item in Sequence )
或(expression for item in Sequence if conditional )
实例
1 | a = (x for x in range(1,10)) |
字典(Dict)
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key:value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 。
注意:dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict。
1 | tinydict = {'a': 1, 'b': 2, 'b': '3'} |
访问字典中的值
把相应的键放入熟悉的方括弧,如下实例:
1 | tinydict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'} |
修改字典
如果键存在则修改对应的值,如果键不存在则新增这个键和值。
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
1 | tinydict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'} |
你可以用检查列表和元组是否包含某个值的方法,检查字典中是否包含某个键:
1 | 'Age' in tinydict |
删除字典元素
del
对于字典中不再需要的信息,可使用del语句将相应的键—值对彻底删除。使用del语句时,必须指定字典名和要删除的键。
1 | alien_0 = {'color': 'green', 'points': 5} |
dict.pop(key[,default])
字典 pop() 方法删除字典 key(键)所对应的值,返回被删除的值。
- key - 要删除的键
- default - 当键 key 不存在时返回的值
1 | alien_0 = {'color': 'green', 'points': 5} |
清空字典
dict.clear()
1 | tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} |
遍历字典
遍历所有键值对
dict.items()
以列表返回可遍历的(键, 值) 元组数组。
注意,即便遍历字典时,键—值对的返回顺序也与存储顺序不同。Python不关心键—值对的存储顺序,而只跟踪键和值之间的关联关系。
1 | user_0 = { |
遍历所有键
dict.keys()
返回一个字典所有的键。方法keys()并非只能用于遍历;实际上,它返回一个列表,其中包含字典中的所有键。
1 | favorite_languages = { |
遍历字典时,会默认遍历所有的键,因此,如果将上述代码中的for name in favorite_ languages.keys(): 替换为 for name in favorite_languages:,输出将不变。
遍历所有值
dict.values()
以列表返回一个字典所有的值。
1 | favorite_languages = { |
融合字典
dict.update(dict2)
用update方法可以将一个字典与另一个融合:
1 | d1 = {'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer'} |
update方法是原地改变字典,因此任何传递给update的键的旧的值都会被舍弃。
用序列创建字典
常常,你可能想将两个序列配对组合成字典。下面是一种写法:
1 | mapping = {} |
因为字典本质上是2元元组的集合,dict可以接受二元元组的列表:
1 | key = range(5) |
字典推导式
字典推导基本格式
{ key_expr: value_expr for value in collection }
或{ key_expr: value_expr for value in collection if condition }
实例
1 | listdemo = ['Google','Runoob', 'Taobao'] |
1 | dic = {x: x**2 for x in (2, 4, 6)} |
字典键的特性
字典值可以没有限制地取任何 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
- 不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
1 | tinydict = {'Name': 'Runoob', 'Age': 7, 'Name': 'Manni'} |
- 键必须不可变,所以可以用数字,字符串或元组充当,不可以是列表,如下实例:
1 | tinydict = {['Name']: 'Zara', 'Age': 7} |
内置方法
get()
get() 函数返回指定键的值。
dict.get(key[, value])
key – 字典中要查找的键。
value – 可选,如果指定键的值不存在时,返回该默认值。
1 | tinydict = {'Name': 'Runoob', 'Age': 27} |
get() 方法 Vs dict[key] 访问元素区别
get(key) 方法在 key(键)不在字典中时,可以返回默认值 None 或者设置的默认值。
dict[key] 在 key(键)不在字典中时,会触发 KeyError 异常。
1 | runoob = {} |
keys()
字典 keys() 方法返回一个视图对象。视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。
我们不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
dict.keys()
实例
1 | dishes = {'eggs': 2, 'sausage': 1, 'bacon': 1, 'spam': 500} |
values()
字典 values() 方法返回一个视图对象。视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。
我们不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
dict.values()
实例
1 | dishes = {'eggs': 2, 'sausage': 1, 'bacon': 1, 'spam': 500} |
items()
items() 方法以列表返回视图对象,是一个可遍历的key/value 对。视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。
我们不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
dict.items()
实例
1 | tinydict = {'Name': 'Runoob', 'Age': 7} |
集合(Set)
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,
**创建一个空集合必须用 set() 而不是 { }**,因为 { } 是用来创建一个空字典。
集合的特点
- 自动去除重复数据
- 顺序随机,不支持下标
创建集合
parame = {value01,value02,...}
或者set(value)
实例
1 | basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} |
添加元素
set.add(x)
将元素x添加到集合s中,如果元素已存在,则不进行任何操作。
1 | thisset = set(("Google", "Runoob", "Taobao")) |
set.update(set)
update() 方法用于修改当前集合,可以添加新的元素或集合到当前集合中,如果添加的元素在集合中已存在,则该元素只会出现一次,重复的会忽略。
1 | x = {"apple", "banana", "cherry"} |
删除元素
set.remove(item)
remove() 方法用于移除集合中的指定元素。remove()方法在移除一个不存在的元素时会发生错误。
1 | fruits = {"apple", "banana", "cherry"} |
set.discard(value)
discard() 方法用于移除指定的集合元素。
该方法不同于 remove() 方法,因为 remove() 方法在移除一个不存在的元素时会发生错误,而 discard() 方法不会。
1 | fruits = {"apple", "banana", "cherry"} |
set.pop()
pop()方法用于随机移除一个元素。
1 | fruits = {"apple", "banana", "cherry"} |
判断元素是否在集合中存在
x (not)in s
判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False。
1 | thisset = set(("Google", "Runoob", "Taobao")) |
集合运算
集合支持合并、交集、差分和对称差等数学集合运算。考虑两个示例集合:
1 | a = {1, 2, 3, 4, 5} |
合并是取两个集合中不重复的元素。可以用union方法,或者|运算符:
1 | print(a.union(b)) |
交集的元素包含在两个集合中。可以用intersection或&运算符:
1 | print(a.intersection(b)) |
表3-1列出了常用的集合方法。

集合推导式
集合推导式基本格式:
{ expression for item in Sequence }
或{ expression for item in Sequence if conditional }
实例
1 | setnew = {i**2 for i in (1,2,3)} |
1 | a = {x for x in 'abracadabra' if x not in 'abc'} |
函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号**()**。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
1 | def functionname( parameters ): |
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- 不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
- 可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
传不可变对象实例
1 | def ChangeInt( a ): |
实例中有 int 对象 2,指向它的变量是 b,在传递给 ChangeInt 函数时,按传值的方式复制了变量 b,a 和 b 都指向了同一个 Int 对象,在 a=10 时,则新生成一个 int 值对象 10,并让 a 指向它。
传可变对象实例
1 | # 可写函数说明 def changeme( mylist ): |
实例中传入函数的和在末尾添加新内容的对象用的是同一个引用,故输出结果如下:
1 | 函数内取值: [10, 20, 30, [1, 2, 3, 4]] |
可变参数
位置参数(positional argument)
所谓位置参数,是指用相对位置指代参数。
1 | def functionname([formal_args,] *var_args_tuple ): |
*参数收集所有未匹配的位置参数组成一个tuple对象,局部变量args指向此tuple对象
位置参数实例如下:
1 | def printinfo( arg1, *vartuple): |
关键字参数(keyword argument)
使用关键字指代参数。
1 | def functionname([formal_args,] **var_args_dict ): |
**参数收集所有未匹配的关键字参数组成一个dict对象,局部变量kwargs指向此dict对象
关键词参数实例如下:
1 | def bar(param1, **param2): |
匿名(lambda)函数
python 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法:
lambda [arg1 [,arg2,.....argn]]:expression
实例:
1 | sum = lambda arg1, arg2: arg1 + arg2 |
1 | print((lamda a, b, c=5: a+b+c)(2,6)) |
内置函数
print()
print()方法用于打印输出
print(objects, sep=' ', end='\n', file=sys.stdout, flush=False)
- objects – 复数,表示可以一次输出多个对象。输出多个对象时,需要用 , 分隔。
- sep – 用来间隔多个对象,默认值是一个空格。
- end – 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符串。
- file – 要写入的文件对象。
- flush – 输出是否被缓存通常决定于 file,但如果 flush 关键字参数为 True,流会被强制刷新。
1 | str1 = '111' |
eval()
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
eval(expression[, globals[, locals]])
- expression – 表达式。
- globals – 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
1 | print(eval('2+2')) |
enumerate()
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,可以返回(i, value)元组序列,一般用在 for 循环当中。
enumerate(sequence, [start=0])
实例
1 | seasons = ['Spring', 'Summer', 'Fall', 'Winter'] |
for循环使用enumerate
1 | seq = ['one', 'two', 'three'] |
当你索引数据时,使用enumerate的一个好方法是计算序列(唯一的)dict映射到位置的值:
1 | some_list = ['foo','bar','baz'] |
filter()
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
filter(function, iterable)
1 | tmplist = filter(lambda n: n % 2 == 1, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) |
map()
map() 函数会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
map(function, iterable, ...)
- function – 函数名!!!
- iterable – 一个或多个序列
- 返回一个迭代器输入一行整数,数字之间以空格间隔。输出这些数字组成的完整列表。
1
2
3
4
5
6
7
8
9
10
11def square(x): # 计算平方数
return x ** 2
print(map(square, [1, 2, 3, 4, 5])) # 计算列表各个元素的平方
# <map object at 0x100d3d550> # 返回迭代器
print(list(map(square, [1, 2, 3, 4, 5]))) # 使用 list() 转换为列表
# [1, 4, 9, 16, 25]
print(list(map(lambda x: x ** 2, [1, 2, 3, 4, 5]))) # 使用 lambda 匿名函数
# [1, 4, 9, 16, 25]
1 | str = "1 2 3 4 5" |
sorted()
sorted(iterable, key=None, reverse=False)
- sorted()函数让你能够按特定顺序显示列表元素,同时不影响它们在列表中的原始排列顺序。
- iterable – 可迭代对象。
- key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse – 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
- 返回值返回重新排序的列表。
1 | cars = ['bmw', 'audi', 'toyota', 'subaru'] |
zip()
zip([iterable, ...])
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
我们可以使用 list() 转换来输出列表。
1 | a = [1,2,3] |
给出一个“被压缩的”序列,zip可以被用来解压序列。也可以当作把行的列表转换为列的列表。这个方法看起来有点神奇:
1 | pitchers = [('Nolan', 'Ryan'), ('Roger', 'Clemens'),('Schilling', 'Curt')] |
zip的常见用法之一是同时迭代多个序列,可能结合enumerate使用:
1 | for i, (a, b) in enumerate(zip(seq1, seq2)): |
reversed()
reversed(seq)
reversed 函数返回一个反转的迭代器。
- seq – 要转换的序列,可以是 tuple, string, list 或 range。
1 | print(list(reversed(range(10)))) |
要记住reversed是一个生成器,只有实体化(即列表或for循环)之后才能创建翻转的序列。
setattr()
setattr(object, name, value)
setattr() 函数对应函数 getattr(),用于设置属性值,该属性不一定是存在的。
如果属性不存在会创建一个新的对象属性,并对属性赋值。
- object – 对象。
- name – 字符串,对象属性。
- value – 属性值。
1 | class A(object): |
hasattr()
hasattr(object, name)
hasattr() 函数用于判断对象是否包含对应的属性。
- object – 对象。
- name – 字符串,属性名。
1 | class Coordinate: |
getattr()
getattr(object, name[, default])
getattr() 函数用于返回一个对象属性值。
- object – 对象。
- name – 字符串,对象属性。
- default – 默认返回值,如果不提供该参数,在没有对应属性时,将触发 AttributeError。
1 | class A(object): |
三元表达式
python中的三元操作符可以使用 if-else 语句也就是条件操作符的一个快捷方式:
value = true-expr if condition else false-expr
true-expr或false-expr可以是任何Python代码。它和下面的代码效果相同:
1 | if condition: |
举例:
1 | sex = 1 |
文件处理
文件打开
Python open() 方法用于打开一个文件,并返回文件对象。
在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。最常使用的是两个位置参数和一个关键字参数:open(filename, mode, encoding=None)
f = open('workfile', 'w', encoding="utf-8")
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
mode 参数有:
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| t | 文本模式 (默认)。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(Python 3 不支持)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
b二进制;+可读可写r、rb、r+、rb+: 只要文件不存在就报错,指针放在文件开头w、wb、w+、wb+: 只要文件不存在就新建文件,指针放在文件开头,用新内容覆盖原内容a、ab、a+、ab+: 只要文件不存在就新建文件,指针放在文件结尾
With关键字
在处理文件对象时,最好使用 with 关键字。优点是,子句体结束后,文件会正确关闭,即便触发异常也可以。而且,使用 with 相比等效的 try-finally代码块要简短得多:
1 | with open('workfile', encoding="utf-8") as f: |
警告:调用 f.write() 时,未使用 with 关键字,或未调用 f.close(),即使程序正常退出,也可能导致 f.write() 的参数没有完全写入磁盘。
文件对象读写
file.read()
read() 方法用于从文件读取指定的字符数(文本模式 t)或字节数(二进制模式 b),如果未给定参数 size 或 size 为负数则读取文件所有内容。如已到达文件末尾,f.read() 返回空字符串('')。
1 | # 打开文件 |
file.readline()
f.readline()从文件中读取单行数据;字符串末尾保留换行符(\n),只有在文件不以换行符结尾时,文件的最后一行才会省略换行符。这种方式让返回值清晰明确;只要 f.readline()返回空字符串,就表示已经到达了文件末尾,空行使用 '\n' 表示,该字符串只包含一个换行符。
1 | f.readline() |
从文件中读取多行时,可以用循环遍历整个文件对象。这种操作能高效利用内存,快速,且代码简单:
1 | for line in f: |
file.readlines()
readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for… in … 结构进行处理。 如果碰到结束符 EOF 则返回空字符串。
1 | f.readlines() |
如需以列表形式读取文件中的所有行,可以用 list(f) 或 f.readlines()。
file.write()
write() 方法用于向文件中写入指定字符串,并返回写入的字符数。
在文件关闭前或缓冲区刷新前,字符串内容存储在缓冲区中,这时你在文件中是看不到写入的内容的。
1 | r = f.write('This is a test\n') |
file.tell()
返回整数,给出文件对象在文件中的当前位置,表示为二进制模式下时从文件开始的字节数,以及文本模式下的意义不明的数字。
file.seek()
seek() 方法用于移动文件读取指针到指定位置。
f.seek(offset, whence)
- offset – 开始的偏移量,也就是代表需要移动偏移的字节数,如果是负数表示从倒数第几位开始。
- whence:可选,默认值为 0。给 offset 定义一个参数,表示要从哪个位置开始偏移;0 代表从文件开头开始算起,1 代表从当前位置开始算起,2 代表从文件末尾算起。
1 | f = open('workfile', 'rb+') |
NumPy
NumPy是一个功能强大的Python库,主要用于对多维数组执行计算。NumPy这个词来源于两个单词– Numerical和Python。
Ndarray 对象
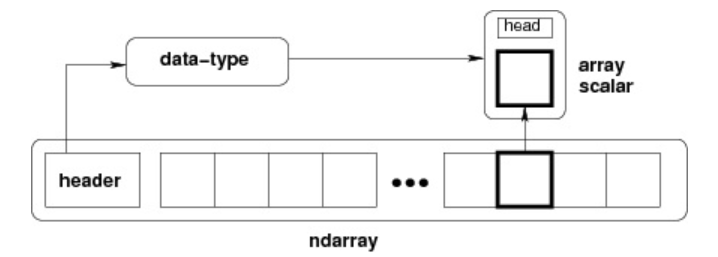
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要”跨过”的字节数。
numpy.array
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
参数说明:
| 名称 | 描述 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
1 | import numpy as np |
数组属性
NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
| 属性 | 说明 |
|---|---|
| ndarray.ndim | 秩,即轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
| ndarray.flags | ndarray 对象的内存信息 |
| ndarray.real | ndarray元素的实部 |
| ndarray.imag | ndarray 元素的虚部 |
| ndarray.data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 |
1 | a = np.array([[11, 12, 13, 14, 15], |
创建数组
numpy.arange
numpy 包中的使用 arange 函数创建数值范围并返回 ndarray 对象,函数格式如下:
numpy.arange(start, stop, step, dtype)
根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray。
参数说明:
| 参数 | 描述 |
|---|---|
| start | 起始值,默认为0 |
| stop | 终止值(不包含) |
| step | 步长,默认为1 |
| dtype | 返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。 |
1 | import numpy as np |
numpy.empty
numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
numpy.empty(shape, dtype = float, order = 'C')
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | 有”C”和”F”两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。 |
1 | import numpy as np |
numpy.zeros
创建指定大小的数组,数组元素以 0 来填充:
numpy.zeros(shape, dtype = float, order = 'C')
参数说明:
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | ‘C’ 用于 C 的行数组,或者 ‘F’ 用于 FORTRAN 的列数组 |
1 | import numpy as np |
numpy.ones
创建指定形状的数组,数组元素以 1 来填充:
numpy.ones(shape, dtype = None, order = 'C')
参数说明:
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | ‘C’ 用于 C 的行数组,或者 ‘F’ 用于 FORTRAN 的列数组 |
1 | import numpy as np |
numpy.zeros_like
numpy.zeros_like 用于创建一个与给定数组具有相同形状的数组,数组元素以 0 来填充。
numpy.zeros 和 numpy.zeros_like 都是用于创建一个指定形状的数组,其中所有元素都是 0。
它们之间的区别在于:numpy.zeros 可以直接指定要创建的数组的形状,而 numpy.zeros_like 则是创建一个与给定数组具有相同形状的数组。
numpy.zeros_like(a, dtype=None, order='K', subok=True, shape=None)
参数说明:
| 参数 | 描述 |
|---|---|
| a | 给定要创建相同形状的数组 |
| dtype | 创建的数组的数据类型 |
| order | 数组在内存中的存储顺序,可选值为 ‘C’(按行优先)或 ‘F’(按列优先),默认为 ‘K’(保留输入数组的存储顺序) |
| subok | 是否允许返回子类,如果为 True,则返回一个子类对象,否则返回一个与 a 数组具有相同数据类型和存储顺序的数组 |
| shape | 创建的数组的形状,如果不指定,则默认为 a 数组的形状。 |
创建一个与 arr 形状相同的,所有元素都为 0 的数组:
1 | import numpy as np |
numpy.ones_like
numpy.ones_like 用于创建一个与给定数组具有相同形状的数组,数组元素以 1 来填充。
numpy.ones 和 numpy.ones_like 都是用于创建一个指定形状的数组,其中所有元素都是 1。
它们之间的区别在于:numpy.ones 可以直接指定要创建的数组的形状,而 numpy.ones_like 则是创建一个与给定数组具有相同形状的数组。
numpy.ones_like(a, dtype=None, order='K', subok=True, shape=None)
参数说明:
| 参数 | 描述 |
|---|---|
| a | 给定要创建相同形状的数组 |
| dtype | 创建的数组的数据类型 |
| order | 数组在内存中的存储顺序,可选值为 ‘C’(按行优先)或 ‘F’(按列优先),默认为 ‘K’(保留输入数组的存储顺序) |
| subok | 是否允许返回子类,如果为 True,则返回一个子类对象,否则返回一个与 a 数组具有相同数据类型和存储顺序的数组 |
| shape | 创建的数组的形状,如果不指定,则默认为 a 数组的形状。 |
创建一个与 arr 形状相同的,所有元素都为 1 的数组:
1 | import numpy as np |
numpy.linspace
numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,格式如下:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
参数说明:
| 参数 | 描述 |
|---|---|
| start | 序列的起始值 |
| stop | 序列的终止值,如果endpoint为true,该值包含于数列中 |
| num | 要生成的等步长的样本数量,默认为50 |
| endpoint | 该值为 true 时,数列中包含stop值,反之不包含,默认是True。 |
| retstep | 如果为 True 时,生成的数组中会显示间距,反之不显示。 |
| dtype | ndarray 的数据类型 |
以下实例用到三个参数,设置起始点为 1 ,终止点为 10,数列个数为 10。
1 | import numpy as np |
切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
我们可以通过冒号:分隔切片参数 [start:stop:step] 来进行切片操作:
下面的图表说明了给定的示例切片是如何进行工作的。

切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。
1 | import numpy as np |
数组索引
以下实例获取数组中 (0,0),(1,1) 和 (2,0) 位置处的元素。
1 | import numpy as np |
可以借助切片:或 … 与索引数组组合。如下面例子:
1 | import numpy as np |
布尔索引
我们可以通过一个布尔数组来索引目标数组。
布尔索引通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组。
以下实例获取大于 5 的元素:
1 | import numpy as np |
假设每个名字都对应data数组中的一行,而我们想要选出对应于用户”andy”的所有行。
1 | import numpy as np |
要选择除”andy”以外的其他值,既可以使用不等于符号(!=),也可以通过~对条件进行否定:
1 | print(data[~(names == 'andy')]) |
花式索引
花式索引指的是利用整数数组进行索引。
花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。
对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素,如果目标是二维数组,那么就是对应下标的行。
花式索引跟切片不一样,它总是将数据复制到新数组中。
一维数组
一维数组只有一个轴 axis = 0,所以一维数组就在 axis = 0 这个轴上取值:
1 | import numpy as np |
二维数组
1 | import numpy as np |
数组操作
修改数组形状
| 函数 | 描述 |
|---|---|
| reshape | 不改变数据的条件下修改形状 |
| flat | 数组元素迭代器 |
| flatten | 返回一份数组拷贝,对拷贝所做的修改不会影响原始数组 |
| ravel | 返回展开数组 |
numpy.reshape
numpy.reshape 函数可以在不改变数据的条件下修改形状,格式如下:
numpy.reshape(arr, newshape, order='C')
- arr:要修改形状的数组
- newshape:整数或者整数数组,新的形状应当兼容原有形状
- order:’C’ – 按行,’F’ – 按列,’A’ – 原顺序,’k’ – 元素在内存中的出现顺序。
1 | import numpy as np |
数组转置和轴对换
转置是重塑的一种特殊形式,它返回的是源数据的视图(不会进行任何复制操作)。数组不仅有transpose方法,还有一个特殊的T属性:
1 | import numpy as np |
在进行矩阵计算时,经常需要用到该操作,比如利用np.dot计算矩阵内积:
1 | import numpy as np |
对于高维数组,transpose需要得到一个由轴编号组成的元组才能对这些轴进行转置(比较费脑子):
1 | import numpy as np |
简单的转置可以使用.T,它其实就是进行轴对换而已。ndarray还有一个swapaxes方法,它需要接受一对轴编号:
arr.swapaxes(1,2)(实际上等价于arr.swapaxes(2,1)),将轴1和轴2进行互换。
1 | import numpy as np |
swapaxes也是返回源数据的视图(不会进行任何复制操作)。
利用数组进行数据处理
将条件逻辑表述为数组运算
numpy.where函数是三元表达式x if condition else y的矢量化版本。假设我们有一个布尔数组和两个值数组,我们想要根据cond中的值选取xarr和yarr的值:当cond中的值为True时,选取xarr的值,否则从yarr中选取。列表推导式的写法应该如下所示:
1 | import numpy as np |
这有几个问题。第一,它对大数组的处理速度不是很快(因为所有工作都是由纯Python完成的)。第二,无法用于多维数组。若使用np.where,则可以将该功能写得非常简洁:
1 | result = np.where(cond, xarr, yarr) |
np.where的第二个和第三个参数不必是数组,它们都可以是标量值。在数据分析工作中,where通常用于根据另一个数组而产生一个新的数组。假设有一个由随机数据组成的矩阵,你希望将所有正值替换为’正数’,将所有负值替换为’负数’。若利用np.where,则会非常简单:
1 | import numpy as np |
使用np.where,可以将标量和数组结合起来。例如,可用常数2替换arr中所有正的值:
1 | print(np.where(arr>0,2,arr)) |
数学和统计方法
可以通过数组上的一组数学函数对整个数组或某个轴向的数据进行统计计算。sum、mean以及标准差std等聚合计算(aggregation,通常叫做约简(reduction))既可以当做数组的实例方法调用,也可以当做顶级NumPy函数使用。
1 | import numpy as np |
mean和sum这类的函数可以接受一个axis选项参数,用于计算该轴向上的统计值,最终结果是一个少一维的数组:
1 | print(arr.mean(axis=1)) |
表4-5列出了全部的基本数组统计方法。


用于布尔型数组的方法
在上面这些方法中,布尔值会被强制转换为1(True)和0(False)。因此,sum经常被用来对布尔型数组中的True值计数(注意:是计数不是求和!!!):
1 | import numpy as np |
另外还有两个方法any和all,它们对布尔型数组非常有用。any用于测试数组中是否存在一个或多个True,而all则检查数组中所有值是否都是True:
1 | import numpy as np |
这两个方法也能用于非布尔型数组,所有非0元素将会被当做True。
排序
跟Python内置的列表类型一样,NumPy数组也可以通过sort方法就地排序:
1 | import numpy as np |
多维数组可以在任何一个轴向上进行排序,只需将轴编号传给sort即可:
1 | import numpy as np |
唯一化以及其它的集合逻辑
NumPy提供了一些针对一维ndarray的基本集合运算。最常用的可能要数np.unique了,它用于找出数组中的唯一值并返回已排序的结果:
1 | import numpy as np |
另一个函数np.in1d用于测试一个数组中的值在另一个数组中的成员资格,返回一个布尔型数组:
1 | import numpy as np |
NumPy中的集合函数请参见 表4-6。
表4-6。
深拷贝&浅拷贝
概述
b = a
对象b引用对象a,对象b本身没有单独分配内存空间,它指向计算机中存储对象a的内存。a和b相互影响,b发生变化了,b也会发生变化。
b = a.view() or b=a[:]
a 和 b 并不同属一块内存,是两个不同的对象。对 b 的修改会改变 a。
b = a.copy()
ndarray.copy()函数创建一个副本。 对副本数据进行修改,不会影响到原始数据,它们物理内存不在同一位置。
完全不复制
简单分配不会复制数组对象或其数据。
1 | import numpy as np |
视图或浅拷贝
不同的数组对象可以共享相同的数据。用view方法创建一个查看相同数据的新数组对象。
view方法可以新建一个新的 ndarray,但是只会 copy 父对象,不会 copy 底层的数据,共用原始引用指向的对象数据。a和b相互影响,b发生变化了,b也会发生变化。
NumPy中,一个ndarray的视图和原ndarray是不同的对象,但是共享ndarray值的内存。这两个对象是相互关联的,这样的好处是不会涉及到数据在内存中的复制,这样可以节省空间,提高性能。
1 | import numpy as np |
切片数组会返回一个视图:
1 | s = a[ : , 1:3] # spaces added for clarity; could also be written "s = a[:,1:3]" |
深拷贝
1 | import numpy as np |
有时,如果不再需要原始数组,则应在切片后调用 copy。例如,假设a是一个巨大的中间结果,最终结果b只包含a的一小部分,那么在用切片构造b时应该做一个深拷贝:
1 | a = np.arange(int(1e8)) |
Pandas
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
Pandas是基于NumPy数组构建的,特别是基于数组的函数和不使用for循环的数据处理。虽然Pandas采用了大量的NumPy编码风格,但二者最大的不同是Pandas是专门为处理表格和混杂数据设计的。而NumPy更适合处理统一的数值数组数据。
数据结构
| 维数 | 名称 | 描述 |
|---|---|---|
| 1 | Series | 带标签的一维同构数组 |
| 2 | DataFrame | 带标签的,大小可变的,二维异构表格 |
Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生最简单的Series:
pandas.Series( data, index, dtype, name, copy)
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
1 | import pandas as pd |
Series的字符串表现形式为:索引在左边,值在右边。由于我们没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
你可以通过Series 的values和index属性获取其数组表示形式和索引对象:
1 | import pandas as pd |
我们可以指定索引值,如下实例:
1 | import pandas as pd |
与普通NumPy数组相比,你可以通过索引的方式选取Series中的单个或一组值:
1 | import pandas as pd |
Series的索引可以通过赋值的方式就地修改:
1 | import pandas as pd |
我们也可以使用 key/value 对象,类似字典来创建 Series:
1 | import pandas as pd |
如果只传入一个字典,则结果Series中的索引就是原字典的键(有序排列)。你可以传入排好序的字典的键以改变顺序:
1 | import pandas as pd |
在这个例子中,sdata中跟states索引相匹配的那3个值会被找出来并放到相应的位置上,但由于”California”所对应的sdata值找不到,所以其结果就为NaN(即“非数字”(not a number),在pandas中,它用于表示缺失或NA值)。因为‘Utah’不在states中,它被从结果中除去。
pandas的isnull和notnull函数可用于检测缺失数据:
1 | import pandas as pd |
Series也有类似的实例方法:
1 | import pandas as pd |
Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系非常密切:
1 | import pandas as pd |
DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
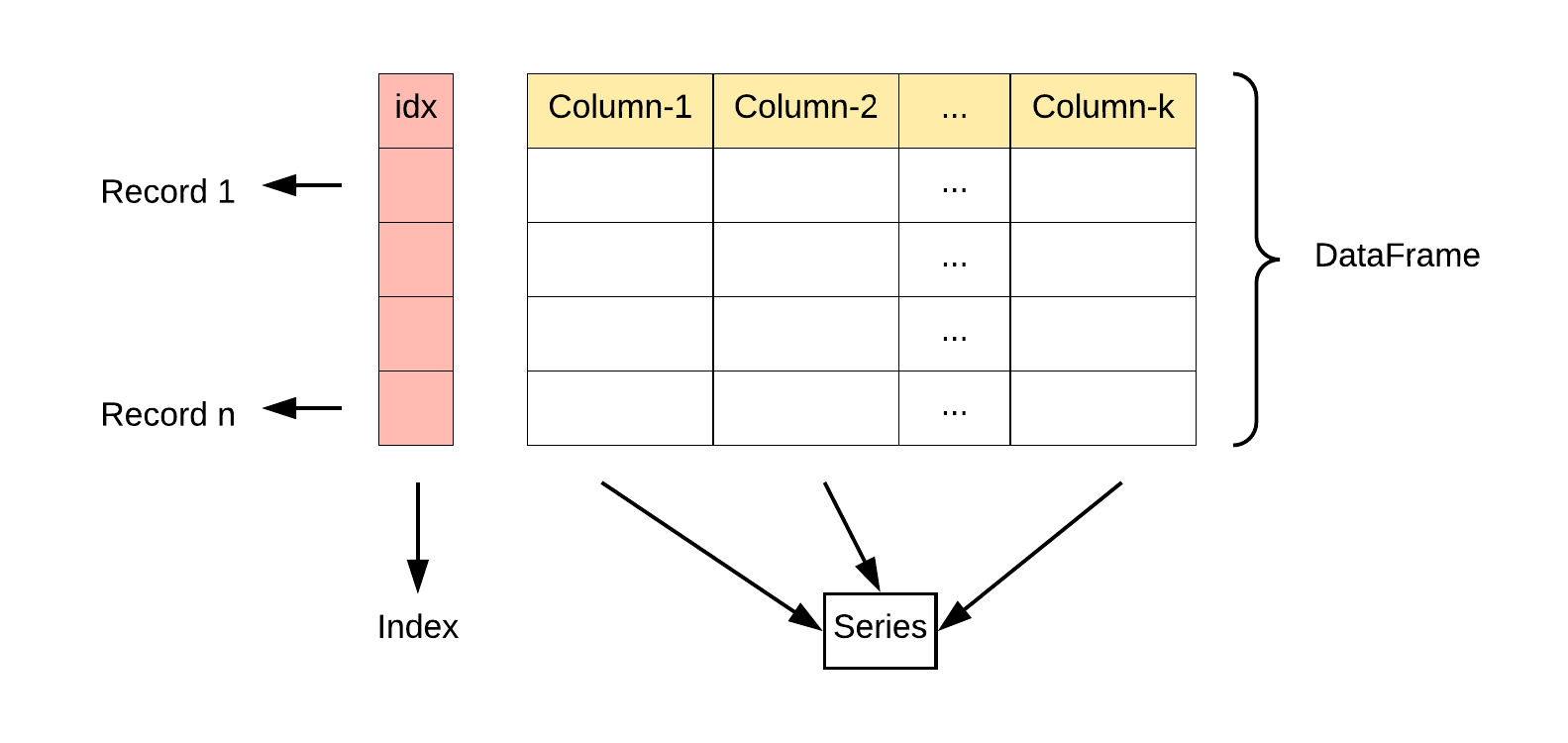
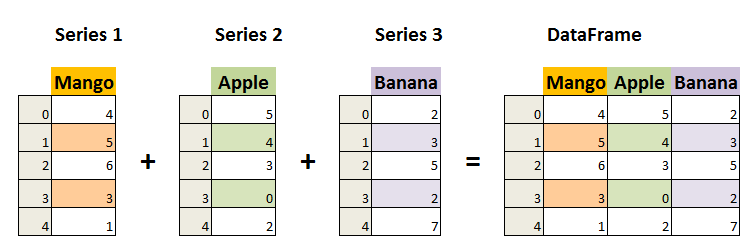
pandas.DataFrame( data, index, columns, dtype, copy)
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
1 | import pandas as pd |
建DataFrame的办法有很多,最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典:
1 | import pandas as pd |
如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列:
1 | import pandas as pd |
如果传入的列在数据中找不到,就会在结果中产生缺失值:
1 | import pandas as pd |
列可以通过赋值的方式进行修改。例如,我们可以给那个空的”debt”列赋上一个标量值或一组值:
1 | import pandas as pd |
将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。如果赋值的是一个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值:
1 | import pandas as pd |
del方法可以用来删除列:
1 | import pandas as pd |
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
1 | import pandas as pd |
常用方法
1 | df.head(5) #查看前5行 |
索引对象
Pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index:
1 | import pandas as pd |
Index对象是不可变的,因此用户不能对其进行修改:
1 | index[1] = 'd' # TypeError |
除了类似于数组,Index的功能也类似一个固定大小的集合:
1 | import pandas as pd |
与python的集合不同,pandas的Index可以包含重复的标签:
1 | import pandas as pd |
每个索引都有一些方法和属性,它们可用于设置逻辑并回答有关该索引所包含的数据的常见问题。表5-2列出了这些函数。

基本功能
重新索引
pandas对象的一个重要方法是reindex,其作用是创建一个新对象,它的数据符合新的索引。

1 | import pandas as pd |
用该Series的reindex将会根据新索引进行重排。如果某个索引值当前不存在,就引入缺失值:
1 | obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e']) |
对于时间序列这样的有序数据,重新索引时可能需要做一些插值处理。method选项即可达到此目的,例如,使用ffill可以实现前向值填充:
1 | import pandas as pd |
借助DataFrame,reindex可以修改(行)索引和列。只传递一个序列时,会重新索引结果的行:
1 | import pandas as pd |
列可以用columns关键字重新索引:
1 | import pandas as pd |
丢弃指定轴上的项
丢弃某条轴上的一个或多个项很简单,只要有一个索引数组或列表即可。由于需要执行一些数据整理和集合逻辑,所以drop方法返回的是一个在指定轴上删除了指定值的新对象:
1 | import numpy as np |
对于DataFrame,可以删除任意轴上的索引值。
1 | import pandas as pd |
用标签序列调用drop会从行标签(axis=0)删除值:
1 | print(data.drop(['Colorado', 'Ohio'])) |
通过传递axis=1或axis=’columns’可以删除列的值:
1 | print(data.drop('two', axis=1)) |
许多函数,如drop,会修改Series或DataFrame的大小或形状,可以就地修改对象,不会返回新的对象:
1 | import pandas as pd |
小心使用inplace,它会销毁所有被删除的数据。
索引、选取和过滤
Series索引(obj[…])的工作方式类似于NumPy数组的索引,只不过Series的索引值不只是整数。下面是几个例子:
1 | import pandas as pd |
利用标签的切片运算与普通的Python切片运算不同,其末端是包含的:
1 | import pandas as pd |
用切片可以对Series的相应部分进行设置:
1 | import pandas as pd |
用一个值或序列对DataFrame进行索引其实就是获取一个或多个列:
1 | import pandas as pd |
这种索引方式有几个特殊的情况。首先通过切片或布尔型数组选取数据:
1 | print(data[:2]) |
另一种用法是通过布尔型DataFrame(比如下面这个由标量比较运算得出的)进行索引,这使得DataFrame的语法与NumPy二维数组的语法很像。
1 | print(data<5) |
query()
DataFrame对象有一个query() 允许使用表达式进行选择的方法。完全类似numpy的语法:
1 | In [232]: df = pd.DataFrame(np.random.randint(10, size=(10, 3)), columns=list('abc')) |
通过删除括号略微更好(通过绑定使比较运算符绑定比&和更紧|)。
1 | In [236]: df.query('a < b & b < c') |
使用英语而不是符号:
1 | In [237]: df.query('a < b and b < c') |
非常接近你如何在纸上写它:
1 | In [238]: df.query('a < b < c') |
query()还支持Python in和 比较运算符的特殊用法,为调用或的方法提供了简洁的语法 。
1 | # get all rows where columns "a" and "b" have overlapping values |
您可以将此与其他表达式结合使用,以获得非常简洁的查询:
1 | # rows where cols a and b have overlapping values |
==运算符与list对象的特殊用法
1 | In [247]: df.query('b == ["a", "b", "c"]') |
用loc和iloc进行选取
对于DataFrame的行的标签索引,引入了特殊的标签运算符loc和iloc。它们可以让你用类似NumPy的标记,使用轴标签(loc)或整数索引(iloc),从DataFrame选择行和列的子集。
1 | import pandas as pd |
用iloc和整数进行选取:
1 | print(data.iloc[2, [3, 0, 1]]) |
这两个索引函数也适用于一个标签或多个标签的切片:
1 | print(data.loc[:'Utah', 'two']) |

整数索引
处理整数索引的pandas对象常常难住新手,因为它与Python内置的列表和元组的索引语法不同。
1 | import pandas as pd |
对于非整数索引,不会产生歧义:
1 | import pandas as pd |
为了进行统一,如果轴索引含有整数,数据选取总会使用标签。为了更准确,请使用loc(标签)或iloc(整数):
1 | import pandas as pd |
算术运算和数据对齐
pandas最重要的一个功能是,它可以对不同索引的对象进行算术运算。在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。
1 | import pandas as pd |
自动的数据对齐操作在不重叠的索引处引入了NA值。缺失值会在算术运算过程中传播。
对于DataFrame,对齐操作会同时发生在行和列上,把它们相加后将会返回一个新的DataFrame,其索引和列为原来那两个DataFrame的并集。
1 | import pandas as pd |
因为’c’和’e’列均不在两个DataFrame对象中,在结果中以缺省值呈现。行也是同样。
如果DataFrame对象相加,没有共用的列或行标签,结果都会是空:
1 | import pandas as pd |
在算术方法中填充值
在对不同索引的对象进行算术运算时,你可能希望当一个对象中某个轴标签在另一个对象中找不到时填充一个特殊值(比如0):
1 | import pandas as pd |
将它们相加时,没有重叠的位置就会产生NA值:
1 | print(df1+df2) |
使用df1的add方法,传入df2以及一个fill_value参数:
1 | print(df1.add(df2, fill_value=0)) |
表5-5列出了Series和DataFrame的算术方法。它们每个都有一个副本,以字母r开头,它会翻转参数。因此这两个语句是等价的:
1 | print(1 / df1) |

在对Series或DataFrame重新索引时,也可以指定一个填充值:
1 | print(df1.reindex(columns=df2.columns, fill_value=0)) |
DataFrame和Series之间的运算
跟不同维度的NumPy数组一样,DataFrame和Series之间算术运算也是有明确规定的。
1 | arr = np.arange(12.).reshape((3, 4)) |
当我们从arr减去arr[0],每一行都会执行这个操作。这就叫做广播(broadcasting)。DataFrame和Series之间的运算差不多也是如此:
1 | import pandas as pd |
默认情况下,DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着行一直向下广播:
1 | print(frame - series) |
如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集:
1 | series2 = pd.Series(range(3), index=['b', 'e', 'f']) |
如果你希望匹配行且在列上广播,则必须使用算术运算方法。例如:
1 | import pandas as pd |
传入的轴号就是希望匹配的轴。在本例中,我们的目的是匹配DataFrame的行索引(axis=’index’ or axis=0)并进行广播。
函数应用和映射
NumPy的ufuncs(元素级数组方法)也可用于操作pandas对象:
1 | import pandas as pd |
另一个常见的操作是,将函数应用到由各列或行所形成的一维数组上。DataFrame的apply方法即可实现此功能:
1 | f = lambda x: x.max() - x.min() |
这里的函数f,计算了一个Series的最大值和最小值的差,在frame的每列都执行了一次。结果是一个Series,使用frame的列作为索引。
如果传递axis=’columns’到apply,这个函数会在每行执行:
1 | print(frame.apply(f, axis='columns')) |
许多最为常见的数组统计功能都被实现成DataFrame的方法(如sum和mean),因此无需使用apply方法。
元素级的Python函数也是可以用的。假如你想得到frame中各个浮点值的格式化字符串,使用applymap即可:
1 | format = lambda x: '%.2f' % x |
之所以叫做applymap,是因为Series有一个用于应用元素级函数的map方法:
1 | format = lambda x: '%.2f' % x |
排序和排名
sort_index()
根据条件对数据集排序(sorting)也是一种重要的内置运算。要对行或列索引进行排序(按字典顺序),可使用sort_index方法,它将返回一个已排序的新对象:
1 | import pandas as pd |
对于DataFrame,则可以根据任意一个轴上的索引进行排序:
1 | import pandas as pd |
ascending
数据默认是按升序排序的,但也可以降序排序:
1 | frame.sort_index(axis=1, ascending=False) |
sort_values()
若要按值对Series进行排序,可使用其sort_values方法:
1 | obj = pd.Series([4, 7, -3, 2]) |
在排序时,任何缺失值默认都会被放到Series的末尾:
1 | obj = pd.Series([4, np.nan, 7, np.nan, -3, 2]) |
当排序一个DataFrame时,你可能希望根据一个或多个列中的值进行排序。将一个或多个列的名字传递给sort_values的by选项即可达到该目的:
1 | frame = pd.DataFrame({'b': [4, 7, -3, 2], 'a': [0, 1, 0, 1]}) |
要根据多个列进行排序,传入名称的列表即可:
1 | frame.sort_values(by=['a', 'b']) |
接下来介绍Series和DataFrame的rank方法。默认情况下,rank是通过“为各组分配一个平均排名”的方式破坏平级关系的:
1 | obj = pd.Series([7, -5, 7, 4, 2, 0, 4]) |
如果两个数值相同,排名是它们的均值,例如数值7在Series中排6、7,平均值为6.5。
也可以根据值在原数据中出现的顺序给出排名:
1 | print(obj.rank(method='first')) |
这里,条目0和2没有使用平均排名6.5,它们被设成了6和7,因为数据中标签0位于标签2的前面。
你也可以按降序进行排名:
1 | print(obj.rank(ascending=False, method='max')) |

带有重复标签的轴索引
1 | obj = pd.Series(range(5), index=['a', 'a', 'b', 'b', 'c']) |
索引的is_unique属性可以告诉你它的值是否是唯一的:
1 | print(obj.index.is_unique) |
对于带有重复值的索引,数据选取的行为将会有些不同。如果某个索引对应多个值,则返回一个Series;而对应单个值的,则返回一个标量值:
1 | print(obj['a']) |
这样会使代码变复杂,因为索引的输出类型会根据标签是否有重复发生变化。
对DataFrame的行进行索引时也是如此:
1 | df = pd.DataFrame(np.random.randn(4, 3), index=['a', 'a', 'b', 'b']) |
汇总和计算描述统计
pandas对象拥有一组常用的数学和统计方法。它们大部分都属于约简和汇总统计,用于从Series中提取单个值(如sum或mean)或从DataFrame的行或列中提取一个Series。跟对应的NumPy数组方法相比,它们都是基于没有缺失数据的假设而构建的。
1 | import numpy as np |
sum()
调用DataFrame的sum方法将会返回一个含有列的和的Series:
1 | print(df.sum()) |
skipna
NA值会自动被排除,除非整个切片(这里指的是行或列)都是NA。通过skipna选项可以禁用该功能:
1 | print(df.mean(axis='columns')) |
表5-7列出了这些约简方法的常用选项。

idxmax()
有些方法(如idxmin和idxmax)返回的是间接统计(比如达到最小值或最大值的索引):
1 | print(df.idxmax()) |
cumsum()
另一些方法则是累计型的:
1 | print(df.cumsum()) |
describe()
还有一种方法,它既不是约简型也不是累计型。describe就是一个例子,它用于一次性产生多个汇总统计:
1 | print(df.describe()) |
对于非数值型数据,describe会产生另外一种汇总统计:
1 | obj = pd.Series(['a', 'a', 'b', 'c'] * 2) |
unique()
它可以得到Series中的唯一值数组:
1 | obj = pd.Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c']) |
返回的唯一值是未排序的,如果需要的话,可以对结果再次进行排序(uniques.sort())。
nunique()
计算指定轴中不同元素的数量。
Series.nunique(dropna=True)
1 | s = pd.Series([1, 3, 5, 7, 7]) |
DataFrame.nunique(axis=0, dropna=True)
1 | df = pd.DataFrame({'A': [4, 5, 6], 'B': [4, 1, 1]}) |
1 | df.nunique(axis=1) |
value_counts()
相似的,value_counts用于计算一个Series中各值出现的频率:
1 | print(obj.value_counts()) |
为了便于查看,结果Series是按值频率降序排列的。value_counts还是一个顶级pandas方法,可用于任何数组或序列:
1 | print(pd.value_counts(obj.values, sort=False)) |
isin用于判断矢量化集合的成员资格,可用于过滤Series中或DataFrame列中数据的子集:
1 | obj = pd.Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c']) |
与isin类似的是Index.get_indexer方法,它可以给你一个索引数组,从可能包含重复值的数组到另一个不同值的数组:
1 | to_match = pd.Series(['c', 'a', 'b', 'b', 'c', 'a']) |
表5-9给出了这几个方法的一些参考信息。

统计函数一览表
| 函数 | 公式 | 含义 |
|---|---|---|
| describe() | DataFrame.describe(percentiles=None, include=None, exclude=None) | 描述性统计(一次性返回多个统计结果) |
| min() | DataFrame.min(axis=0, skipna=True, numeric_only=False, **kwargs) | 计算最小值 |
| max() | DataFrame.max(axis=0, skipna=True, numeric_only=False, **kwargs) | 计算最大值 |
| sum() | DataFrame.sum(axis=None, skipna=True, numeric_only=False, min_count=0, **kwargs) | 求和 |
| mean() | DataFrame.mean(axis=0, skipna=True, numeric_only=False, **kwargs) | 计算平均值 |
| count() | DataFrame.count(axis=0, numeric_only=False) | 计数(统计非缺失元素的个数) |
| size | DataFrame.size | 计数(统计所有元素的个数) |
| median() | DataFrame.median(axis=0, skipna=True, numeric_only=False, **kwargs) | 计算中位数 |
| var() | DataFrame.var(axis=None, skipna=True, ddof=1, numeric_only=False, **kwargs) | 计算方差 |
| std() | DataFrame.std(axis=None, skipna=True, ddof=1, numeric_only=False, **kwargs) | 计算标准差 |
| quantile() | DataFrame.quantile(q=0.5, axis=0, numeric_only=False, interpolation=’linear’, method=’single’) | 计算任意分位数,如四分位数q=0.25 |
| cov() | DataFrame.cov(min_periods=None, ddof=1, numeric_only=False) | 计算协方差 |
| corr() | DataFrame.corr(method=’pearson’, min_periods=1, numeric_only=False) | 计算相关系数 |
| skew() | DataFrame.skew(axis=0, skipna=True, numeric_only=False, **kwargs) | 计算偏度 |
| kurt() | DataFrame.kurt(axis=0, skipna=True, numeric_only=False, **kwargs) | 计算峰度 |
| mode() | DataFrame.mode(axis=0, numeric_only=False, dropna=True) | 计算众数 |
| groupby() | DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True) | 分组 |
| aggregate() | DataFrame.aggregate(func=None, axis=0, *args, **kwargs) | 聚合运算(可以自定义统计函数) |
| idxmin() | DataFrame.idxmin(axis=0, skipna=True, numeric_only=False) | 寻找最小值所在位置 |
| idxmax() | DataFrame.idxmax(axis=0, skipna=True, numeric_only=False) | 寻找最大值所在位置 |
| any() | DataFrame.any(*, axis=0, bool_only=None, skipna=True, **kwargs) | 等价于逻辑“或” |
| all() | DataFrame.all(axis=0, bool_only=None, skipna=True, **kwargs) | 等价于逻辑“与” |
| value_counts() | DataFrame.value_counts(subset=None, normalize=False, sort=True, ascending=False, dropna=True) | 频次统计 |
| cumsum() | DataFrame.cumsum(axis=None, skipna=True, *args, **kwargs) | 运算累计和 |
| cumprod() | DataFrame.cumprod(axis=None, skipna=True, *args, **kwargs) | 运算累计积 |
数据加载与存储
Excel文件
pandas的ExcelFile类或pandas.read_excel函数支持读取存储在Excel 2003(或更高版本)中的表格型数据。这两个工具分别使用扩展包xlrd和openpyxl读取XLS和XLSX文件。你可以用pip或conda安装它们。
要使用ExcelFile,通过传递xls或xlsx路径创建一个实例:
1 | In [104]: xlsx = pd.ExcelFile('examples/ex1.xlsx') |
存储在表单中的数据可以read_excel读取到DataFrame:
1 | In [105]: pd.read_excel(xlsx, 'Sheet1') |
如果要读取一个文件中的多个表单,创建ExcelFile会更快,但你也可以将文件名传递到pandas.read_excel:
1 | In [106]: frame = pd.read_excel('examples/ex1.xlsx', 'Sheet1') |
to_excel
1 | import pandas as pd |
如果要将pandas数据写入为Excel格式,你必须首先创建一个ExcelWriter,然后使用pandas对象的to_excel方法将数据写入到其中:
1 | In [108]: writer = pd.ExcelWriter('examples/ex2.xlsx') |
你还可以不使用ExcelWriter,而是传递文件的路径到to_excel:
1 | In [111]: frame.to_excel('examples/ex2.xlsx') |
set_index
设置索引
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
参数:
- keys: 列名或列名的列表。
- drop: 布尔值,如果为真,将删除用于索引的列。
- append: 如果为真,将该列添加到现有的索引列中。
- inplace: 在数据框架中进行更改,如果是真的。
- verify_integrity: 检查新的索引列是否重复,如果是的话。
更改索引列
1 | import pandas as pd |
CSV & 文本文件
read_csv()
常用参数
filepath_or_buffer: 文件路径,URL或者具有read()方法的任何对象(比如可打开的文件)sep: str,默认分隔符为,, read_table()方法,分隔符为\theader: 当选择默认值或header=0时,将首行设为列名。如果列名被传入明确值就令header=None。注意,当header=0时,即使列名被传参也会被覆盖。names: 列名列表的使用. 如果文件不包含列名,那么应该设置header=None。 列名列表中不允许有重复值。index_col: 索引的列号或列名,可以是一个字符串名称或者数字,也可以是一个分层索引。skiprows: 从文件开始处,需要跳过的行数或行号列表。encoding: 文本编码,例如utf-8
nrows: 从文件开头处读入的行数
首先我们来看一个以逗号分隔的(CSV)文本文件:
1 | In [8]: !cat examples/ex1.csv |
由于该文件以逗号分隔,所以我们可以使用read_csv将其读入一个DataFrame:
1 | In [9]: df = pd.read_csv('examples/ex1.csv') |
read_table()
我们还可以使用read_table,并指定分隔符:
1 | In [11]: pd.read_table('examples/ex1.csv', sep=',') |
并不是所有文件都有标题行。看看下面这个文件:
1 | In [12]: !cat examples/ex2.csv |
自定义行/列名
读入该文件的办法有两个。你可以让pandas为其分配默认的列名,也可以自己定义列名names:
1 | In [13]: pd.read_csv('examples/ex2.csv', header=None) |
假设你希望将message列做成DataFrame的索引。你可以明确表示要将该列放到索引4的位置上,也可以通过index_col参数指定”message”:
1 | In [15]: names = ['a', 'b', 'c', 'd', 'message'] |
如果希望将多个列做成一个层次化索引,只需传入由列编号或列名组成的列表即可:
1 | In [17]: !cat examples/csv_mindex.csv |
有些情况下,有些表格可能不是用固定的分隔符去分隔字段的(比如空白符或其它模式)。看看下面这个文本文件:
1 | In [20]: list(open('examples/ex3.txt')) |
自定义分隔符
虽然可以手动对数据进行规整,这里的字段是被数量不同的空白字符间隔开的。这种情况下,你可以传递一个正则表达式作为read_table的分隔符。可以用正则表达式表达为\s+,于是有:
1 | In [21]: result = pd.read_table('examples/ex3.txt', sep='\s+') |
这里,由于列名比数据行的数量少,所以read_table推断第一列应该是DataFrame的索引。
这些解析器函数还有许多参数可以帮助你处理各种各样的异形文件格式(表6-2列出了一些)。比如说,你可以用skiprows跳过文件的第一行、第三行和第四行:
1 | In [23]: !cat examples/ex4.csv |
缺失值处理是文件解析任务中的一个重要组成部分。缺失数据经常是要么没有(空字符串),要么用某个标记值表示。默认情况下,pandas会用一组经常出现的标记值进行识别,比如NA及NULL:
1 | In [25]: !cat examples/ex5.csv |
na_values可以用一个列表或集合的字符串表示缺失值:
1 | In [29]: result = pd.read_csv('examples/ex5.csv', na_values=['NULL']) |
字典的各列可以使用不同的NA标记值:
1 | In [31]: sentinels = {'message': ['foo', 'NA'], 'something': ['two']} |
表6-2列出了pandas.read_csv和pandas.read_table常用的选项。



逐块读取文本文件
在处理很大的文件时,或找出大文件中的参数集以便于后续处理时,你可能只想读取文件的一小部分或逐块对文件进行迭代。
在看大文件之前,我们先设置pandas显示地更紧些:
1 | In [33]: pd.options.display.max_rows = 10 |
然后有:
1 | In [34]: result = pd.read_csv('examples/ex6.csv') |
nrows
如果只想读取几行(避免读取整个文件),通过nrows进行指定即可:
1 | In [36]: pd.read_csv('examples/ex6.csv', nrows=5) |
chunksize
要逐块读取文件,可以指定chunksize(行数):
1 | In [874]: chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000) |
read_csv所返回的这个TextParser对象使你可以根据chunksize对文件进行逐块迭代。比如说,我们可以迭代处理ex6.csv,将值计数聚合到”key”列中,如下所示:
1 | chunker = pd.read_csv('examples/ex6.csv', chunksize=1000) |
然后有:
1 | In [40]: tot[:10] |
TextParser还有一个get_chunk方法,它使你可以读取任意大小的块。
to_csv()
利用DataFrame的to_csv方法,我们可以将数据写到一个以逗号分隔的文件中:
DataFrame.to_csv(path_or_buf="", sep=",")
常用参数
path_or_buf:必填项,要写入的文件或文件对象的字符串路径。如果是文件对象,则必须使用打开该对象sep:输出文件的字段分隔符(默认为“,”)na_rep: 缺失数据填充,(默认为””)columns:要写入的列(默认为“无”)header:是否写出列名(默认为True)index:是否写入行(索引)名称(默认为True)index_label: 索引列的列标签(如果需要)。如果无(默认值),并且header和index为True,则使用索引名称。(如果DataFrame使用MultiIndex,则应给出序列)。mode:Python写入模式,默认为“w”encoding:输出文件中使用的编码格式,默认为”utf-8”
1 | In [41]: data = pd.read_csv('examples/ex5.csv') |
1 | In [43]: data.to_csv('examples/out.csv') |
当然,还可以使用其他分隔符(由于这里直接写出到sys.stdout,所以仅仅是打印出文本结果而已):
1 | In [45]: import sys |
缺失值在输出结果中会被表示为空字符串。你可能希望将其表示为别的标记值:
1 | In [47]: data.to_csv(sys.stdout, na_rep='NULL') |
如果没有设置其他选项,则会写出行和列的标签。当然,它们也都可以被禁用:
1 | In [48]: data.to_csv(sys.stdout, index=False, header=False) |
此外,你还可以只写出一部分的列,并以你指定的顺序排列:
1 | In [49]: data.to_csv(sys.stdout, index=False, columns=['a', 'b', 'c']) |
Series也有一个to_csv方法:
1 | In [50]: dates = pd.date_range('1/1/2000', periods=7) |
处理分隔符格式
大部分存储在磁盘上的表格型数据都能用pandas.read_table进行加载。然而,有时还是需要做一些手工处理。由于接收到含有畸形行的文件而使read_table出毛病的情况并不少见。为了说明这些基本工具,看看下面这个简单的CSV文件:
1 | In [54]: !cat examples/ex7.csv |
对于任何单字符分隔符文件,可以直接使用Python内置的csv模块。将任意已打开的文件或文件型的对象传给csv.reader:
1 | import csv |
对这个reader进行迭代将会为每行产生一个元组(并移除了所有的引号):
1 | In [56]: for line in reader: |
现在,为了使数据格式合乎要求,你需要对其做一些整理工作。我们一步一步来做。首先,读取文件到一个多行的列表中:
1 | In [57]: with open('examples/ex7.csv') as f: |
然后,我们将这些行分为标题行和数据行:
1 | In [58]: header, values = lines[0], lines[1:] |
然后,我们可以用字典构造式和zip(*values),后者将行转置为列,创建数据列的字典:
1 | In [59]: data_dict = {h: v for h, v in zip(header, zip(*values))} |
CSV文件的形式有很多。只需定义csv.Dialect的一个子类即可定义出新格式(如专门的分隔符、字符串引用约定、行结束符等):
1 | class my_dialect(csv.Dialect): |
各个CSV语支的参数也可以用关键字的形式提供给csv.reader,而无需定义子类:
1 | reader = csv.reader(f, delimiter='|') |
可用的选项(csv.Dialect的属性)及其功能如表6-3所示。

笔记:对于那些使用复杂分隔符或多字符分隔符的文件,csv模块就无能为力了。这种情况下,你就只能使用字符串的split方法或正则表达式方法re.split进行行拆分和其他整理工作了。
要手工输出分隔符文件,你可以使用csv.writer。它接受一个已打开且可写的文件对象以及跟csv.reader相同的那些语支和格式化选项:
1 | with open('mydata.csv', 'w') as f: |
缺失数据处理
在许多数据分析工作中,缺失数据是经常发生的。pandas的目标之一就是尽量轻松地处理缺失数据。例如,pandas对象的所有描述性统计默认都不包括缺失数据。
缺失数据在pandas中呈现的方式有些不完美,但对于大多数用户可以保证功能正常。对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据。我们称其为哨兵值,可以方便的检测出来:
1 | In [10]: string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado']) |
在pandas中,我们采用了R语言中的惯用法,即将缺失值表示为NA,它表示不可用not available。在统计应用中,NA数据可能是不存在的数据或者虽然存在,但是没有观察到(例如,数据采集中发生了问题)。当进行数据清洗以进行分析时,最好直接对缺失数据进行分析,以判断数据采集的问题或缺失数据可能导致的偏差。
Python内置的None值在对象数组中也可以作为NA:
1 | In [13]: string_data[0] = None |
滤除缺失数据
过滤掉缺失数据的办法有很多种。你可以通过pandas.isnull或布尔索引的手工方法,但dropna可能会更实用一些。对于一个Series,dropna返回一个仅含非空数据和索引值的Series:
dropna()
DataFrame.dropna(*, axis=0, how=_NoDefault.no_default, thresh=_NoDefault.no_default, subset=None, inplace=False, ignore_index=False)
- axis:可以是0或1,表示删除行或者列。默认为0。
- how:删除的方式,可以是’any’或’all’。’any’表示只要存在缺失值就删除,’all’表示所有的值都是缺失值才删除。默认为’any’。
- thresh:可以是整数,表示这一行或列最少要有多少个非缺失值才不被删除。如果设置为None,表示所有数据值都需要进行判断。默认为None。
- subset:可以是列名称或列名称的列表,表示只在这些列中进行删除操作。默认为None。
- inplace:True表示直接修改原数据集;False表示返回删除后的新数据集。默认为False。
1 | In [15]: from numpy import nan as NA |
这等价于:
1 | In [18]: data[data.notnull()] |
而对于DataFrame对象,事情就有点复杂了。你可能希望丢弃全NA或含有NA的行或列。dropna默认丢弃任何含有缺失值的行:
1 | In [19]: data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA], |
传入how=’all’将只丢弃全为NA的那些行:
1 | In [23]: data.dropna(how='all') |
用这种方式丢弃列,只需传入axis=1即可:
1 | In [24]: data[4] = NA |
另一个滤除DataFrame行的问题涉及时间序列数据。假设你只想留下一部分观测数据,可以用thresh参数实现此目的:
1 | In [27]: df = pd.DataFrame(np.random.randn(7, 3)) |
填充缺失数据
你可能不想滤除缺失数据(有可能会丢弃跟它有关的其他数据),而是希望通过其他方式填补那些“空洞”。对于大多数情况而言,fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为那个常数值:
fillna()
DataFrame.fillna(value=None, *, method=None, axis=None, inplace=False, limit=None, downcast=None)
- value:用于填充缺失值的值,可以是标量、字典、Series 或 DataFrame。
- method:填充缺失值的方法,可选值包括
backfill(向前填充)、bfill(向后填充)、pad(用前面的非缺失数据填充)、ffill(用后面的非缺失数据填充)等。 - axis:指定在哪个轴上执行填充操作。
- inplace:是否在原 DataFrame 上直接进行修改。
- limit:对于前向填充和后向填充,限制填充缺失值的最大数量。
- downcast:指定填充后的数据类型,可选值包括
infer(自动推断)、integer(整型)等。
1 | In [33]: df.fillna(0) |
若是通过一个字典调用fillna,就可以实现对不同的列填充不同的值:
1 | In [34]: df.fillna({1: 0.5, 2: 0}) |
fillna默认会返回新对象,但也可以对现有对象进行就地修改:
1 | In [35]: _ = df.fillna(0, inplace=True) |
对reindexing有效的那些插值方法也可用于fillna:
1 | In [37]: df = pd.DataFrame(np.random.randn(6, 3)) |
只要有些创新,你就可以利用fillna实现许多别的功能。比如说,你可以传入Series的平均值或中位数:
1 | In [43]: data = pd.Series([1., NA, 3.5, NA, 7]) |
数据转换
移除重复数据
DataFrame中出现重复行有多种原因。下面就是一个例子:
1 | import pandas as pd |
duplicated()
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行(前面出现过的行):
1 | print(data.duplicated()) |
drop_duplicates()
df.drop_duplicates(subset=['A','B'],keep='first',inplace=True)
subset: 输入要进行去重的列名,默认为None
keep: 可选参数有三个:‘first’、 ‘last’、 False, 默认值为 ‘first’。其中,first表示: 保留第一次出现的重复行,删除后面的重复行。last表示: 删除重复项,保留最后一次出现。False表示: 删除所有重复项。
inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。
1 | print(data.drop_duplicates()) |
这两个方法默认会判断全部列,你也可以指定部分列进行重复项判断。假设我们还有一列值,且只希望根据k1列过滤重复项:
1 | import pandas as pd |
矢量化字符串方法
Series 支持字符串处理方法,可以非常方便地操作数组里的每个元素。这些方法会自动排除缺失值与空值,这也许是其最重要的特性。这些方法通过 Series 的 str 属性访问,一般情况下,这些操作的名称与内置的字符串方法一致。示例如下:
1 | s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat']) |
.dt 访问器
对于一个datetime类型的字段,在dataframe中日期时间类型的列数据也可以进行分割处理,即应用属性接口dt。
Series 提供一个可以简单、快捷地返回 datetime 属性值的访问器。这个访问器返回的也是 Series,索引与现有的 Series 一样。
1 | import pandas as pd |
还可以用 Series.dt.strftime() 把 datetime 的值当成字符串进行格式化,支持与标准 strftime()同样的格式。
1 | # DatetimeIndex |
| 函数 | 含义 |
|---|---|
| dt.date | 年月日 |
| dt.year | 年 |
| dt.month | 月 |
| dt.day | 日 |
| dt.hour | 时 |
| dt.minute | 分 |
| dt.second | 秒 |
| dt.week | 一年中的第几周 |
| dt.weekday / dt.day_of_week | 一周中的星期几(0代表星期一) |
| dt.day_name() | 对于英文星期名称 |
| dt.month_name() | 对应英文月份名称 |
| dt.dayofyear / dt.dat_of_year | 一年中的第几天 |
| dt.quarter | 一年中的第几个季度 |
| dt.is_leap_year | 是否是闰年 |
日期处理
时间序列数据的意义取决于具体的应用场景,主要有以下几种:
- 时间戳(timestamp),特定的时刻。
- 固定时期(period),如2007年1月或2010年全年。
- 时间间隔(interval),由起始和结束时间戳表示。时期(period)可以被看做间隔(interval)的特例。
- 实验或过程时间,每个时间点都是相对于特定起始时间的一个度量。例如,从放入烤箱时起,每秒钟饼干的直径。
Python标准库包含用于日期(date)和时间(time)数据的数据类型,而且还有日历方面的功能。我们主要会用到datetime、time以及calendar模块。datetime.datetime(也可以简写为datetime)是用得最多的数据类型:
日期和时间数据类型及工具
datetime.datetime
datetime.datetime(year, month, day, hour, minute, second, microsecond)
- 获取某天日期时间。至少传入year, month, day三个参数。
datetime以毫秒形式存储日期和时间。
1 | from datetime import datetime |
datetime.datetime.now()
1 | from datetime import datetime |
datetime.timedelta
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
- 函数所有参数都是可选的并且默认为 0。 这些参数可以是整数或者浮点数,也可以是正数或者负数。
datetime.timedelta()返回类型为datetime.timedelta
timedelta表示两个datetime对象之间的时间差。
可以给datetime对象加上(或减去)一个或多个timedelta,这样会产生一个新对象:
1 | from datetime import timedelta,datetime |
字符串和datetime的相互转换
datetime.strftime()
datetime对象.strftime(format)datetime.strftime(datetime对象, format)
- format: 格式化编码
利用str或strftime方法(传入一个格式化字符串),datetime对象和pandas的Timestamp对象可以被格式化为字符串:
1 | from datetime import datetime |
datetime.strptime()
datetime.strptime(date_string, format)
date_string: 日期字符串
format: 格式化编码
datetime.strptime可以用这些格式化编码将字符串转换为datetime日期:
1 | from datetime import datetime |
datetime.strptime是通过已知格式进行日期解析的最佳方式。但是每次都要编写格式定义是很麻烦的事情,尤其是对于一些常见的日期格式。这种情况下,你可以用dateutil这个第三方包中的parser.parse方法(pandas中已经自动安装好了):
1 | from dateutil.parser import parse |
dateutil可以解析几乎所有人类能够理解的日期表示形式:
1 | print(parse('Jan 31, 1997 10:45 PM')) |
在国际通用的格式中,日出现在月的前面很普遍,传入dayfirst=True即可解决这个问题:
1 | print(parse('6/12/2011', dayfirst=True)) |
pandas.to_datetime()
当csv文件被导入并形成一个数据框架时,文件中的日期时间对象被读取为字符串对象,而不是日期时间对象,因此,对字符串而不是日期时间对象进行时间差等操作非常困难。Pandas的to_datetime()方法有助于将字符串日期时间转换成Python日期时间对象。
pandas.to_datetime (arg, errors=’raise’, dayfirst=False, yearfirst=False, utc=None, box=True, format=None, exact=True, unit=None, infer_datetime_format=False, origin=’unix’, cache=False)
arg: 一个整数、字符串、浮点数、列表或字典对象,用于转换为Date时间对象。
dayfirst: 布尔值,如果为真,则将日期放在首位。
yearfirst: 布尔值,如果为真,则将年份放在前面。
utc: 布尔值,如果为真,则返回UTC的时间。
format: 字符串输入,告诉日、月、年的位置。
to_datetime方法可以解析多种不同的日期表示形式。对标准日期格式(如ISO8601)的解析非常快:
1 | import pandas as pd |
它还可以处理缺失值(None、空字符串等):
NaT(Not a Time)是pandas中时间戳数据的null值。
1 | import pandas as pd |
格式化编码表
| 代码 | 说明 |
|---|---|
| %y | 两位数的年份表示(00-99) |
| %Y | 四位数的年份表示(000-9999) |
| %m | 月份(01-12) |
| %d | 月内中的一天(0-31) |
| %H | 24小时制小时数(0-23) |
| %I | 12小时制小时数(01-12) |
| %M | 分钟数(00=59) |
| %S | 秒(00-59) |
| %a | 本地简化星期名称 |
| %A | 本地完整星期名称 |
| %b | 本地简化的月份名称 |
| %B | 本地完整的月份名称 |
| %c | 本地相应的日期表示和时间表示 |
| %j | 年内的一天(001-366) |
| %p | 本地A.M.或P.M.的等价符 |
| %U | 一年中的星期数(00-53)星期天为星期的开始 |
| %w | 星期(0-6),星期天为星期的开始 |
| %W | 一年中的星期数(00-53)星期一为星期的开始 |
| %x | 本地相应的日期表示 |
| %X | 本地相应的时间表示 |
| %Z | 当前时区的名称 |
| %% | %号本身 |
时间序列
pandas最基本的时间序列类型就是以时间戳(通常以Python字符串或datatime对象表示)为索引的Series:
1 | from datetime import datetime |
这些datetime对象实际上是被放在一个DatetimeIndex中的:
1 | print(ts.index) |
跟其他Series一样,不同索引的时间序列之间的算术运算会自动按日期对齐:
1 | print(ts + ts[::2]) |
pandas用NumPy的datetime64数据类型以纳秒形式存储时间戳:
1 | print(ts.index.dtype) |
DatetimeIndex中的各个标量值是pandas的Timestamp对象:
1 | stamp = ts.index[0] |
只要有需要,TimeStamp可以随时自动转换为datetime对象。此外,它还可以存储频率信息(如果有的话),且知道如何执行时区转换以及其他操作。
日期的范围、频率以及移动
pandas.date_range()
pd.date_range(start=None, end=None, periods=None, freq=‘D’, tz=None, normalize=False, name=None, closed=None, **kwargs)
- start:开始时间
- end:结束时间
- periods:持续时间
- freq:频率,默认天
- normalize:时间参数值正则化到午夜时间戳
- name:索引对象名称
- closed:默认为None的情况下,左闭右闭,left则左闭右开,right则左开右闭
- pd.date_range()默认频率为日历日
- pd.bdate_range()默认频率为工作日
- tz:时区
pandas.date_range可用于根据指定的频率生成指定长度的DatetimeIndex:
1 | import pandas as pd |
默认情况下,date_range会产生按天计算的时间点。如果只传入起始或结束日期,那就还得传入一个表示一段时间的数字:
1 | import pandas as pd |
date_range默认会保留起始和结束时间戳的时间信息(如果有的话):
1 | print(pd.date_range('2012-05-02 12:56:31', periods=5)) |
有时,虽然起始和结束日期带有时间信息,但你希望产生一组被规范化(normalize)到午夜的时间戳。normalize选项即可实现该功能:
1 | print(pd.date_range('2012-05-02 12:56:31', periods=5, normalize=True)) |